| Hadoop Illuminated > Introduction To MapReduce |  |
|---|
| | |
Table of Contents
Once, while working on an eDiscovery system, before Hadoop was born, I had to scale up my computations: whatever I had done on one computer had to work on thirty computers which we had in our racks. I chose to install JBoss on every machine, only to use its JMS messaging, and my computers were talking to each other through that. It was working, but it had its drawbacks:
That was quite upsetting. I started having dreams about stacks of Linux servers, piled one upon another. Then I read about the Fallacies of distributed computing and realized that I had violated all of them.
At the risk of being a spoiler, I will describe how the MapReduce part of Hadoop addresses the problems above. Now, if you don't want to take it easy but would rather design a good multiprocessing system yourself, then take a pause here, create the design, and email it to us . I will trust you that did not cheat by looking ahead. Whether you do this or not, looking at the MapReduce solution gives you an appreciation of how much it provides.
In the previous section I have shown how MapReduce resolves the common instability problems found in homegrown distributed systems. But I really just hinted at it, so now let us explain this in a little more detail.
Nobody likes to be a slave, and up until now we avoided this terminology, calling them workers. In that, we followed the remark from the movie Big Lebowski": "Also, Dude, chinaman is not the preferred nomenclature. Asian-American, please." However, "slave" is the actual term to be used.
MapReduce has a master and slaves, and they collaborate on getting the work done. The master is listed in the "masters" configuration file, and the slaves are listed in the "slaves", and in this way they know about each other. Furthermore, to be a real "master", the node must run a daemon called the "Job Tracker" daemon. The slave, to be able to do its work, must run another daemon, called the "Tasktracker" daemon.
The master does not divide all the work beforehand, but has an algorithm on how to assign the next portion of the work. Thus, no time is spent up front, and the job can begin right away. This division of labor, how much to give to the next Tasktracker, is called "split", and you have control over it. By default, the input file is split into chunks of about 64MB in size. About, because complete lines in the input file have to be preserved.
Recall that in my system I gave the responsibility for selecting the next piece of work to the workers. This created two kinds of problems. When a worker crashed, nobody knew about it. Of course, the worker would mark the work as "done" after it was completed, but when it crashed, there was nobody to do this for him, so it kept hanging. You needed watchers over watchers, and so on. Another problem would be created when two overzealous workers wanted the same portion. There was a need to somehow coordinate this effort. My solution was a flag in the database, but then this database was becoming the real-time coordinator for multiple processes, and it is not very good at that. You can image multiple scenarios when this would fail.
By contrast, in MapReduce the Job Tracker doles out the work. There is no contention: it takes the next split and assigns it to the next available Tasktracker. If a Tasktracker crashes, it stops sending heartbeats to the Job Tracker.
MapReduce works on data that resides in HDFS. As described in the previous section, HDFS (Hadoop Distributed File System) is unlimited and linearly scalable, that is, it grows by adding servers. Thus the problem of a central files server, with its limited capacity, is eliminated.
Moreover, MapReduce never updates data, rather, it writes a new output instead. This is one of the principles of functional programming , and it avoids update lockups. It also avoids the need to coordinate multiple processes writing to the same file; instead, each Reducer writes to its own output file in an HDFS directory, designated as output for the given job. The Reducer's output file is named using the Reducer ID, which is unique. In further processing, MapReduce will treat all of the files in the input directory as its input, and thus having multiple files either in the input or the output directory is no problem.
As it turns out, network bandwidth is probably the most precious and scarce resource in a distributed system and should be used with care. It is a problem which I have not seen even in my eDiscovery application, because it needs to be correct and stable before optimizing, and getting there is not an easy task.
MapReduce, however, notes where the data is (by using the IP address of the block of data that needs to be processed) and it also knows where the Task Tracker is (by using its IP address). If it can, MapReduce assigns the computation to the server which has the data locally, that is, whose IP address is the same as that of the data. Every Task Tracker has a copy of the code that does the computation (the job's jar, in the case of Java code), and thus the computation can begin.
If local computation is not possible, MapReduce can select the server that is at least closest to the data, so that the network traffic will go through the least number of hops. It does it by comparing the IPs, which have the distance information encoded. Naturally, servers in the same rack are considered closer to each other than servers on different racks. This property of MapReduce to follow the network configuration is called "rack awareness". You set the rack information in the configuration files and reap the benefits.
MapReduce is not like the usual programming models we grew up with. To illustrate the MapReduce model, lets look at an example.
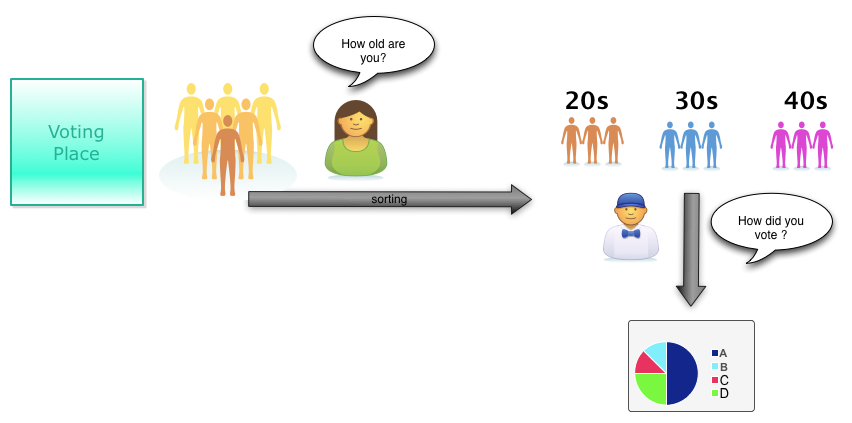
The example we choose is taking 'Exit Polling'. Say there is a election in progress. People are voting at the polling places. To predict election results lot of polling organizations conduct 'exit polling'. It is a fancy way of saying they interview voters exiting the polling place and ask them how they voted.
So for our problem, say we want to understand how different age groups voted. We want to understand how people aged 20s, 30s and 40s voted.
We are going to divide the problem into two phases
The following image explains this.
The 'sorter' (the girl asking 'how old are you') only concerned about sorting people into appropriate groups (in our case, age). She isn't concerned about the next step of compute.
In MapReduce parlance the girl is known as MAPPER
Once the participants are sorted into appropriate age groups, then the guy wearing 'bowtie' just interviews that particular age group to produce the final result for that group. There are few subtle things happening here:
In MapReduce parlance the guy-wearing-bowtie is known as REDUCER
According to an article in "Wired" magazine entitled "If Xerox PARC Invented the PC, Google Invented the Internet all of modern computer science was invented at Google. Definitely the MapReduce technology was invented there, by Jeff Dean and Sanjay Ghemawat. To prove the point, here are some "facts" about Jeff:
Jeff Dean once failed a Turing test when he correctly identified the 203rd Fibonacci number in less than a second.
Jeff Dean compiles and runs his code before submitting it, but only to check for compiler and CPU bugs.
The speed of light in a vacuum used to be about 35 mph. Then Jeff Dean spent a weekend optimizing physics.
You can read the complete article by the two Google engineers, entitled MapReduce: Simplified Data Processing on Large Clusters and decide for yourself.
So what are the benefits of MapReduce programming? As you can see, it summarizes a lot of the experiences of scientists and practitioners in the design of distributed processing systems. It resolves or avoids several complications of distributed computing. It allows unlimited computations on an unlimited amount of data. It actually simplifies the developer's life. And, although it looks deceptively simple, it is very powerful, with a great number of sophisticated (and profitable) applications written in this framework.
In the other sections of this book we will introduce you to the practical aspects of MapReduce implementation. We will also show you how to avoid it, by using higher-level tools, 'cause not everybody likes to write Java code. Then you will be able to see whether or not Hadoop is for you, or even invent a new framework. Keep in mind though that other developers are also busy inventing new frameworks, so hurry to read more.
| | | |
| Chapter 8. Hadoop Distributed File System (HDFS) -- Introduction |  | Chapter 10. Hadoop Use Cases and Case Studies |